原理
利用RAND()和GROUP BY,以包含RAND()的数据为键进行分组(GROUP BY),在执行过程中,GROUP BY会读取每一行数据,如果已存在相应的键值会更新对应行的值,否则会插入该键值,而插入该键值时会重新执行RAND()函数,而不是用之前读取到的值,如果此时RAND()生成了与已有键值冲突的值,则会导致主键冲突报错,报错格式如下:
ERROR 1062 (23000): Duplicate entry '<group>' for key '<group_key>'其中<group>是前面GROUP BY分组所用的键值。
公式
为了方便观察,我调整了SQL注入语句的格式,其中注释包含的内容是查询语句,要求只能查询返回单个结果的语句
AND
(
SELECT 1 FROM
(
SELECT
COUNT(*),
CONCAT
(
FLOOR(RAND(0)*2),
(
-- query begin --
SELECT
CONCAT
(
0x7e7e3a7e7e,
COUNT(DISTINCT table_schema),
0x7e7e3a7e7e
)
FROM
information_schema.tables
LIMIT 0,1
-- query end --
)
) x
FROM information_schema.tables
GROUP BY x
) a
)整理压缩后:
AND (SELECT 1 FROM (SELECT COUNT(*),CONCAT(FLOOR(RAND(0)*2),(SELECT CONCAT(0x7e7e3a7e7e,COUNT(DISTINCT table_schema),0x7e7e3a7e7e) FROM information_schema.tables LIMIT 0,1)) x FROM information_schema.tables GROUP BY x) a)关键语句
- RAND()
- FLOOR()
- COUNT()
- GROUP BY
RAND()
产生一个 0~1 的伪随机数,加上固定随机数种子后返回的数值序列会固定。RAND(0)*2可以生成 0~2 之间的固定值序列。在公式中用于结合其他函数生成 0,1 的固定序列使键值重复。
FLOOR()
向下取整。FLOOR(RAND(0)*2)可以生成固定的 0,1 值序列。

COUNT()
返回匹配指定条件的行数。COUNT()即为一种简单的聚合函数,可以配合GROUP BY实现分组并聚合数据。
这里不一定要使用
COUNT(),也可以使用其他聚合函数。关于聚合函数的更多知识,这里不作赘述,感兴趣的可以自行搜索。
GROUP BY
用于结合聚合函数,根据一个或多个列对结果集进行分组。
SELECT key_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY key_name;
aggregate_function()表示一种聚合函数
工作过程:
st=>start: 开始
create_tmp_table=>operation: 创建用于存储分组结果的表,并将 key_name 设为主键
read_key_value=>operation: 读取数据集中的一条记录
execute_sub_query=>subroutine: 同时执行数据中的语句
select_data=>operation: 取出所需数据
isExist=>condition: 判断临时表中是否已存在该键值
update_data=>operation: 更新临时表中对应的分组数据
insert_key=>operation: 向临时表插入新组数据
execute_sub_query_again=>subroutine: 重新执行数据中的语句
isReadAll=>condition: 是否读取完毕
ed=>end: 结束
st->create_tmp_table->read_key_value->select_data->execute_sub_query->isExist
isExist(yes)->update_data->isReadAll
isExist(no)->execute_sub_query_again->insert_key->isReadAll
isReadAll(yes)->ed
isReadAll(no)->read_key_value关注到工作流程图中的两个子程序,分别在两次取数据时执行了数据中的子语句,这是该类报错注入的核心,因为两次分别执行了数据中的子语句,导致判断时用的键值和插入时的键值可能不同,从而可能插入已存在的键值,导致主键冲突。
剖析
子查询
在一个SELECT语句里还有一个SELECT语句,里面的这个SELECT语句就是子查询。执行的时候,会先执行子查询。
例如:
SELECT concat((SELECT database()));先执行SELECT database()这个语句就会把当前的数据库查出来,然后把结果传入到concat函数,然后再执行外面的查询。
报错原理
把造成报错的核心语句取出:
SELECT COUNT(*),FLOOR(RAND(0)*2) x FROM information_schema.tables GROUP BY xFLOOR(RAND(0)*2)返回的序列上文已提及
这里我们一步步分析
待会依次调用
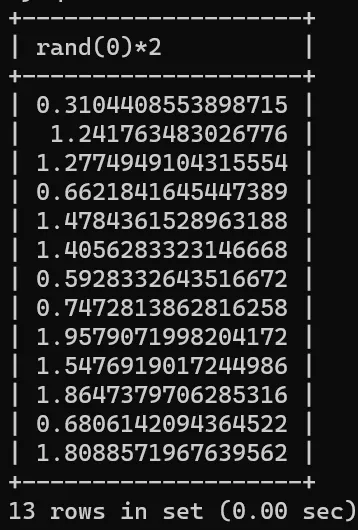
FLOOR(RAND(0)*2),会按顺序返回 [0,1,1,0,1],请记住这个序列。
1. GROUP BY创建了一个临时表
x是FLOOR(RAND(0)*2)的别名
| x | COUNT(*) |
|---|
2. 读取了第一行数据
操作
| 操作 | 结果 |
|---|---|
| 取出第一条数据 | 得到 x, COUNT(*) = 0, 1 |
| 判断临时表是否存在对应键 | 没有 |
| 向临时表插入键值 | 插入 x, COUNT(*) = 1, 1 |
临时表
| x | COUNT(*) |
|---|---|
| 1 | 1 |
3. 读取第二行数据
操作
| 操作 | 结果 |
|---|---|
| 取出第二条数据 | 得到 x, COUNT(*) = 1, 1 |
| 判断临时表是否存在对应键 | 存在 |
| 向临时表更新键值 | x=1, COUNT(*)+1 |
临时表
| x | COUNT(*) |
|---|---|
| 1 | 2 |
4. 读取第三行数据
操作
| 操作 | 结果 |
|---|---|
| 取出第三条数据 | 得到 x, COUNT(*) = 0, 1 |
| 判断临时表是否存在对应键 | 没有 |
| 向临时表插入键值 | 插入 x, COUNT(*) = 1, 1 => 主键冲突报错 |
因为插入时重新生成了另一个 x 值,而此时的 x 为已存在的键,插入造成了主键冲突,产生了报错
实战
- sqli-labs less-5
总结
主键冲突报错注入的原理至此已经阐明。为了不造成读者疑惑,本文中的注入公式采用的是网上流行的版本加以精简,随机数种子也沿用了传统的 0 ,该种子要求所查表中至少要存在三条记录才能报错。
实际上,可以更优化该公式实现两条以上记录就完成报错。具体实现只要找到随机数种子使公式产生 [0,1,0,1] 或 [1,0,1,0] 的序列即可,这里笔者找到随机数种子为 14 时,可以产生 [1,0,1,0] 的序列。